
If we were living in a simulation, in order for humanity to continue its drive out towards longer, happier lives, every now and then something drastic should happen. We should get a serendipitous paradigm shift at the most desperate time. The next paradigm shift is AI. AI may be the technological Shangri-La we were crying out for in order to stop the heating of the planet and ultimately, the end of humanity. This may also be the case with drug discovery. The way in which we find and create new drugs may be about to transform forever.
Drug discovery has come a long way. It started with natural remedies and saw landmark serendipitous discoveries like penicillin in 1928. The mid-20th century introduced rational drug design, targeting specific biological mechanisms. Advances in genomics, high-throughput screening, and computational methods have further accelerated drug development, transforming modern medicine. However, despite these advances, fewer than 10% of drug candidates succeed in clinical trials (Thomas, D. et al. Clinical Development Success Rates and Contributing Factors 2011–2020 (BIO, QLS & Informa, 2021)). Challenges like pharmacokinetics and the complexity of diseases hamper progress. While we no longer fear smallpox or polio and have effective treatments for bacterial infections and Hepatitis C, today’s most damaging diseases are complex and hard to treat due to our limited understanding of their mechanisms.
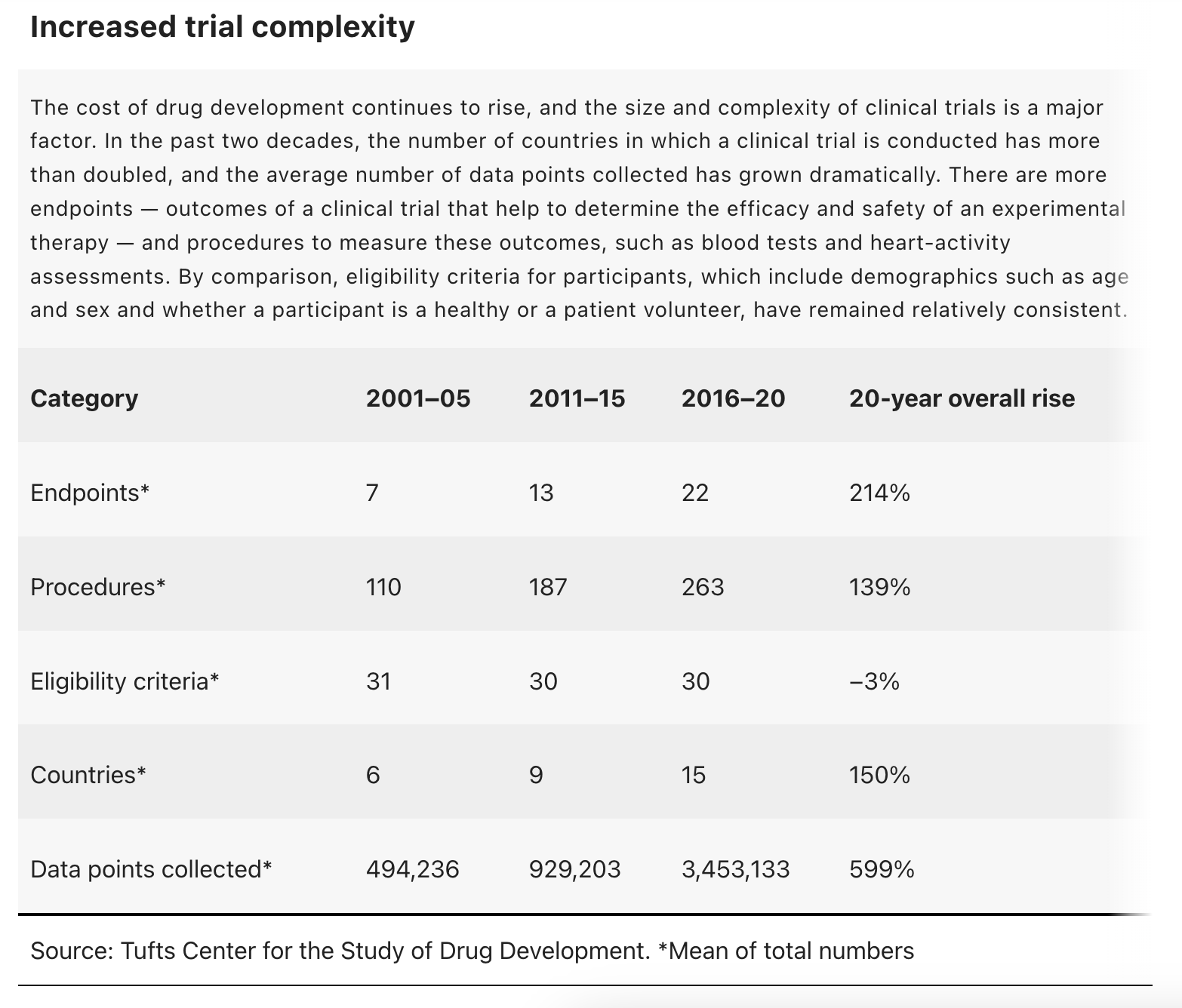
Nature 627, S2-S5 (2024) https://doi.org/10.1038/d41586-024-00753-x
Cue paradigm shift. DeepMind’s AlphaFold has revolutionized biology by accurately predicting protein structures, a task crucial for understanding biological functions and disease mechanisms. The economic prowess of Deepmind is also creating some mind-blowing figures. The estimated replacement cost of current Protein Data Bank archival contents (the dataset from which the AlphaFold models were built) exceeds US$20 billion (assuming an average cost of US$100,000 for regenerating each of the >200,000 experimental structures). AlphaFold has subsequently generated a database of more than 200 million structures. Some back of the envelope maths infers that this would have cost us $20,000,000,000,000 using the original methods.
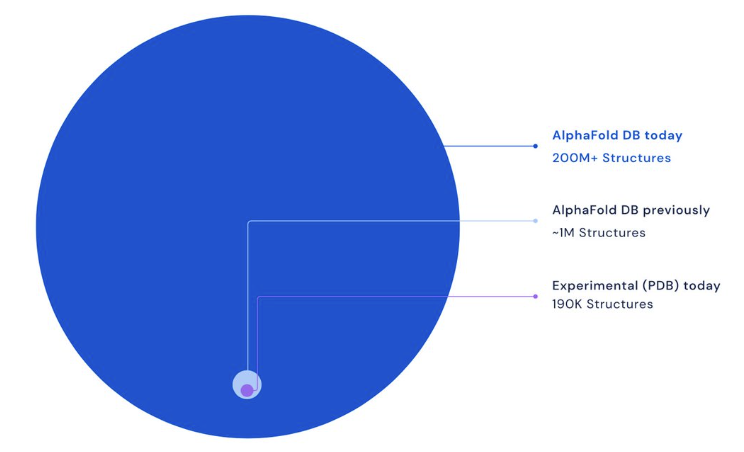
Number of protein structures in Alphafold. Credit: Deepmind
Of course, there are many simultaneous attempts to move the research needle using AI. A team from AI pharma startup Insilico Medicine, working with researchers at the University of Toronto, took 21 days to create 30,000 designs for molecules that target a protein linked with fibrosis (tissue scarring). They synthesized six of these molecules in the lab and then tested two in cells; the most promising one was tested in mice. The researchers concluded it was potent against the protein and showed “drug-like” qualities. All in all, the process took just 46 days. Scottish spinout Exscientia has developed a clinical pipeline for AI-designed drug candidates.
Not only does the platform generate highly optimized molecules that meet the multiple pharmacology criteria required to enter a compound into a clinical trial, it achieves it in revolutionary timescales, cutting the industry average timeline from 4.5 years to just 12 to 15 months. These companies have the technical know-how to build the models, and most likely some internal data with which to train them on. But they need more.
The Power of Existing Data
Platforms like the Dimensions Knowledge Graph, powered by metaphactory, demonstrate the potential of structured data. With over 32 billion statements, it delivers insights derived from global research and public datasets. Connecting internal knowledge with such vast external data provides a trustworthy, explainable layer for AI algorithms, enhancing their application across the pharma value chain.
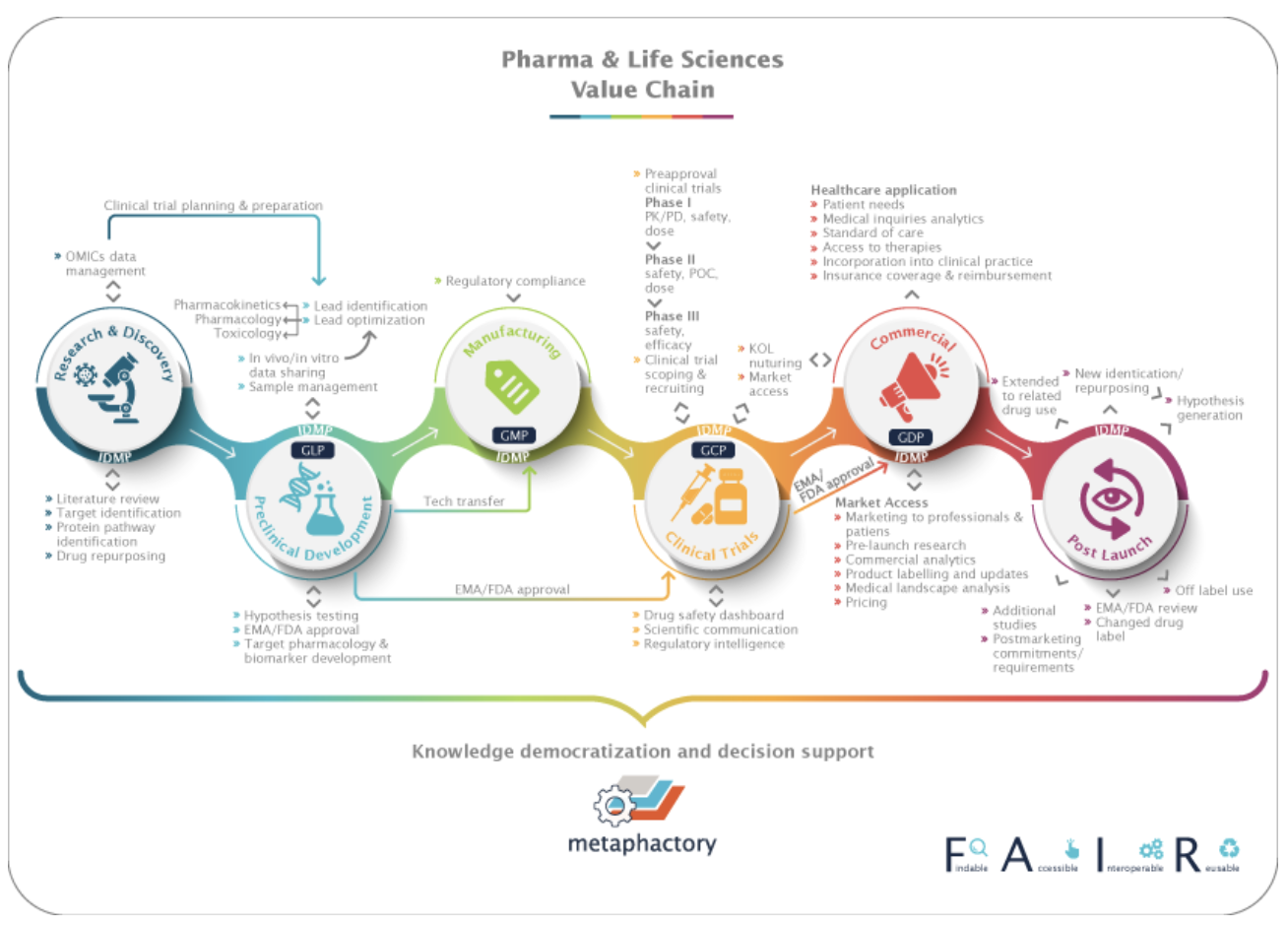
Knowledge democratization bridges the gaps in the pharma value chain. Credit: metaphacts
AI is not all there is to be excited about in drug discovery. A further technological, serendipitous paradigm shift could amplify the results of AI alone. Once trained, machine-learning models can be updated as and when more data become available. With ‘federated learning’, separate parties update a shared model using data sets without sharing the underlying data. Advances in federated learning allow for collaborating across organizations without sharing sensitive data, maintaining privacy while pooling diverse datasets. Federated learning is a machine learning technique that allows models to be trained across multiple companies holding local data samples. Instead of sending data to a central server, each device sends its model updates (e.g., weight changes) to the central server. This allows further reduction in time and cost in the drug discovery process by improving predictive models, without leaking private company held datasets. Public data can augment local datasets held in corporate R&D departments, enriching the training process. Public data with similar characteristics can help in creating more comprehensive models. This is why we need more, better described open academic research data.
Pharmaceutical companies of the world should be engaging further with both open academic data aggregators in order to assist in the improvement of metadata quality and highly curated linked datasets like the ones supported by the Dimensions Knowledge Graph and metaphactory. The limiting factor is not the AI capabilities, it is the amount of high-quality, well described data that they can incorporate into their models. They need to:
- Acquire: Gather data from diverse sources, including internal external datasets. Make use of federated learning.
- Enhance: Enrich data with metadata and standardized formats to improve utility and interoperability.
- Analyse: Use new models to establish patterns, trends and drug candidates.
You may be thinking that this isn’t a serendipitous leap. This is the fruition of decades of research moving us to a point where these technologies can be applied. You may be right. Either way, the timing of these paradigm changing tools does feel serendipitous. Without AI and federated learning, we could not tackle today’s complex diseases in such an efficient manner. There is a long way to go, but by continuing to curate and build on top of academic data, we can push the boundaries of what’s possible in modern medicine.
This is part of a Digital Science series on research transformation. Learn about how we’re tracking transformation here.




























